This post describes how I have configured Visual Studio (2017 is the current version) to look and behave the way I want it to. Writing it down makes it easier for me to repeat the setup the next time I install Visual Studio on a new computer, but maybe someone else will find it useful as well.
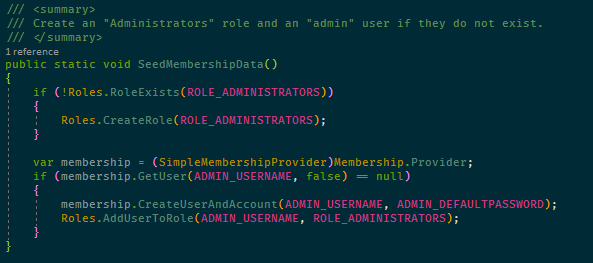
This is how a fragment of C# looks in my Visual Studio:
Color Theme
For years I have been using a color theme called Solarized Dark, of which there are many versions on the web and for many editors. I have modified a few colors but I think (but am not sure anymore) that the version I started with is this one: https://studiostyl.es/schemes/solarized-dark
I have exported my Fonts and Colors setting in Visual Studio to make them easy to reinstall, and this also includes the customized ReSharper colors (see below). Download here and use the Tools/Import and Export Settings… option in Visual Studio.
Font
The font I use is called Fira Code and supports programming ligatures which means that some combinations of characters are shown as custom symbols, such as in the lamba expression in this code fragment:![]()
Fira Code can be downloaded directly from its GitHub repository: https://github.com/tonsky/FiraCode
Install it into Windows by downloading the contents of the distr/ttf folder and install the different variants of the font by right-clicking on them in the File Explorer and select Install in the context menu. Then go to Visual Studio’s Tools/Options menu option, to Environment/Fonts and Colors and select the font you want. I use the Fira Code Medium variant as it looked the best on my monitor.
Visual Studio Extensions
Setting the color theme and the font is still not enough to get the Visual Studio look the way I want. To go the whole way I also need two Visual Studio extensions: ReSharper and Viasfora.
ReSharper
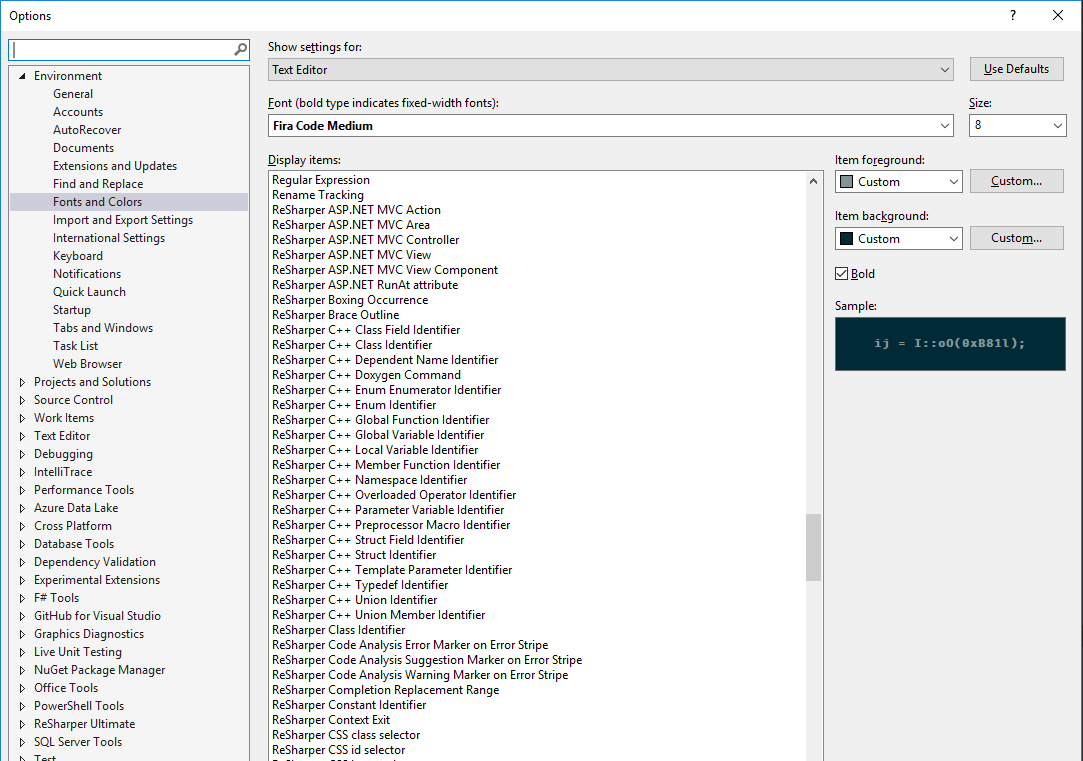
If you’re using Visual Studio for any serious work, chances are you’re already using ReSharper because of its very powerful coding tools such as the code suggestions and refactoring features. It also extends Visual Studio’s syntax highlighting with many more coloring rules. This can be seen in the Fonts and Colors dialog where these colors can be customized:
However, the coloring rules are not used unless ReSharper’s syntax coloring is enabled, as it’s disabled by default. The reason for this is probably that it does affect editing performance a little but if you have a powerful machine I think it’s worth enabling them. Not doing this leaves you with something like this:
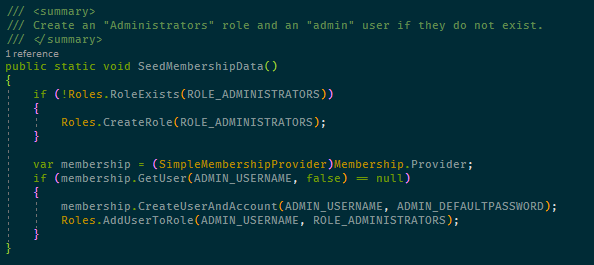
Compared to the example at the beginning of this post there are differences in that constants and methods are not colored, which I think they should be.
To enable the feature, go to ReSharper options and find the Code Inspection/Settings page and enable Color identifiers:
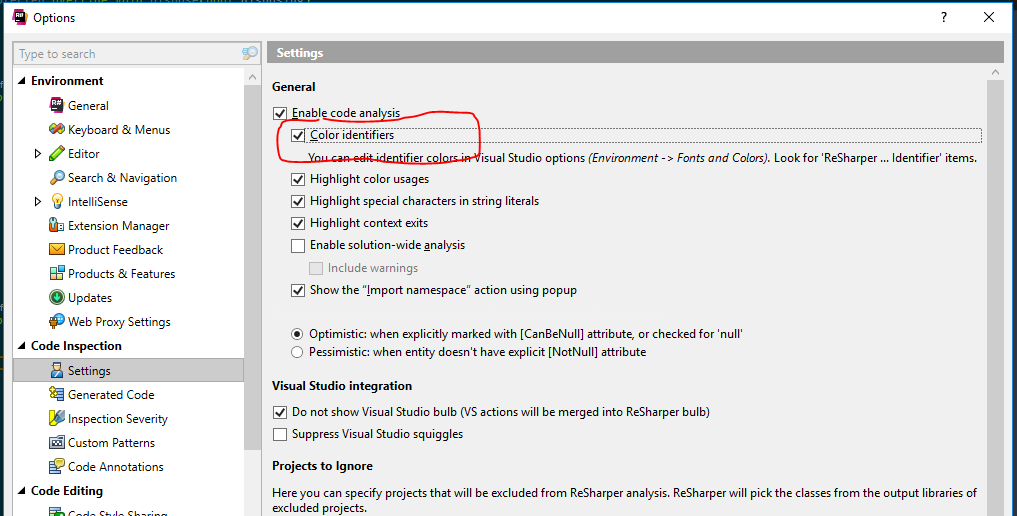
Since you’re already in ReSharper settings, you might also find it useful to enable the Use CamelHumps setting in Environment/Editor/Editor behavior. This is a feature which changes the definition of word delimiters when editing so that when moving the cursor to the next or previous word (Ctrl + Right/Left Arrow), it stops at upper case characters in camel cased symbols. Very useful for moving into long symbol names if you need to change something in the middle of them.
Viasfora
Viasfora is a fairly recent acquaintance of mine and I have found it useful to add the final coloring behaviors I want:
- Rainbow parenthesis
I didn’t know I needed it before I saw it, but now I find it very useful to have parenthesis and bracket pairs to have matching colors which are different from the colors of nested parentheses. Makes it much easier to see parenthesis mistakes when writing code. Visasfora has this feature and the colors it uses are customizable too. - Customizable colors for some keywords
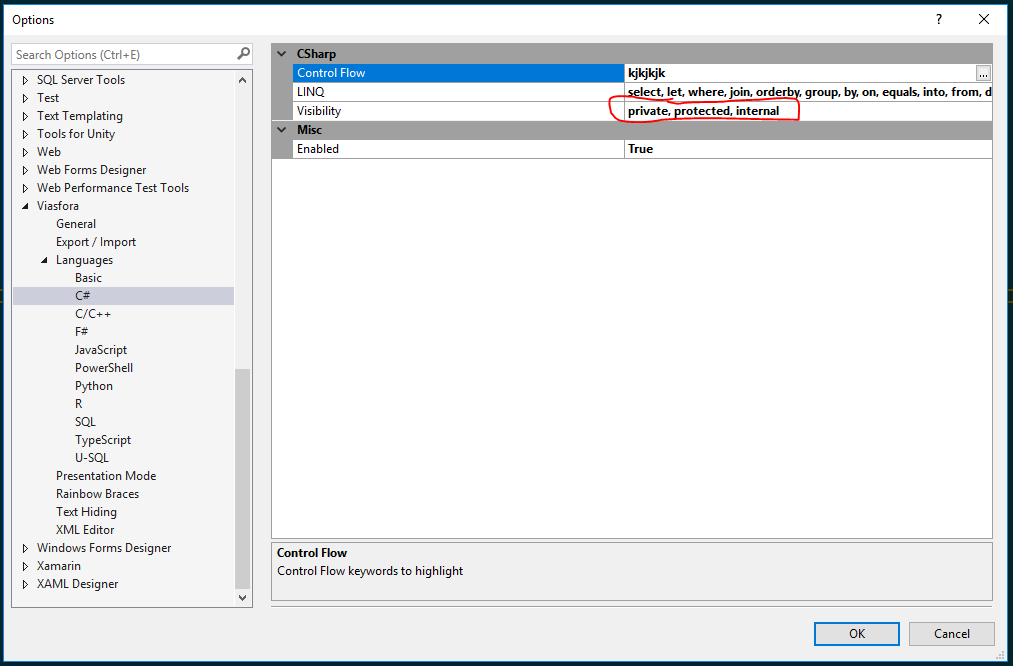
It has for quite some time disturbed me that all visibility keywords in C# are colored the same. I really need private and public to be colored differently to make it easier to see the exposed surface of a class. Viasfora doesn’t exactly have this feature, but it does its own keyword coloring which will override Visual Studio’s built-in coloring. And its list of keywords is editable, so I can for example remove all keywords that I don’t want Viasfora to color and then set the color it uses to a discrete gray:
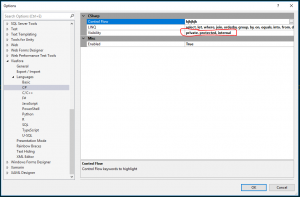
This is the result and as you can see, it’s very easy to see the difference between public and private members: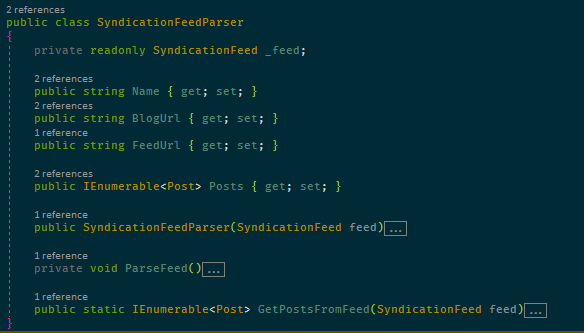
Final comments
A lot of the above has to do with aesthetics but I don’t think it’s only about making the editing experience “look good”, which anyway is rather subjective. I firmly believe in minimizing the mental energy spent on interpreting and understanding code so that more energy can be put into solving the actual problems. With the changes above, I don’t have too look up symbols to see if they’re constants or enums or variables and it’s easy to see what methods are public. I think this makes me a little bit faster and my code a little bit better. That it’s nicer to look at the code is a bonus 🙂
Good luck with fiddling with configuration on your own, and feel free to post suggestions in the comments. Improving the development experience is a task I never expect to finish so new ideas are always welcome!
/Emil